Addressing Monotonous Voiceovers with Context-Aware AI
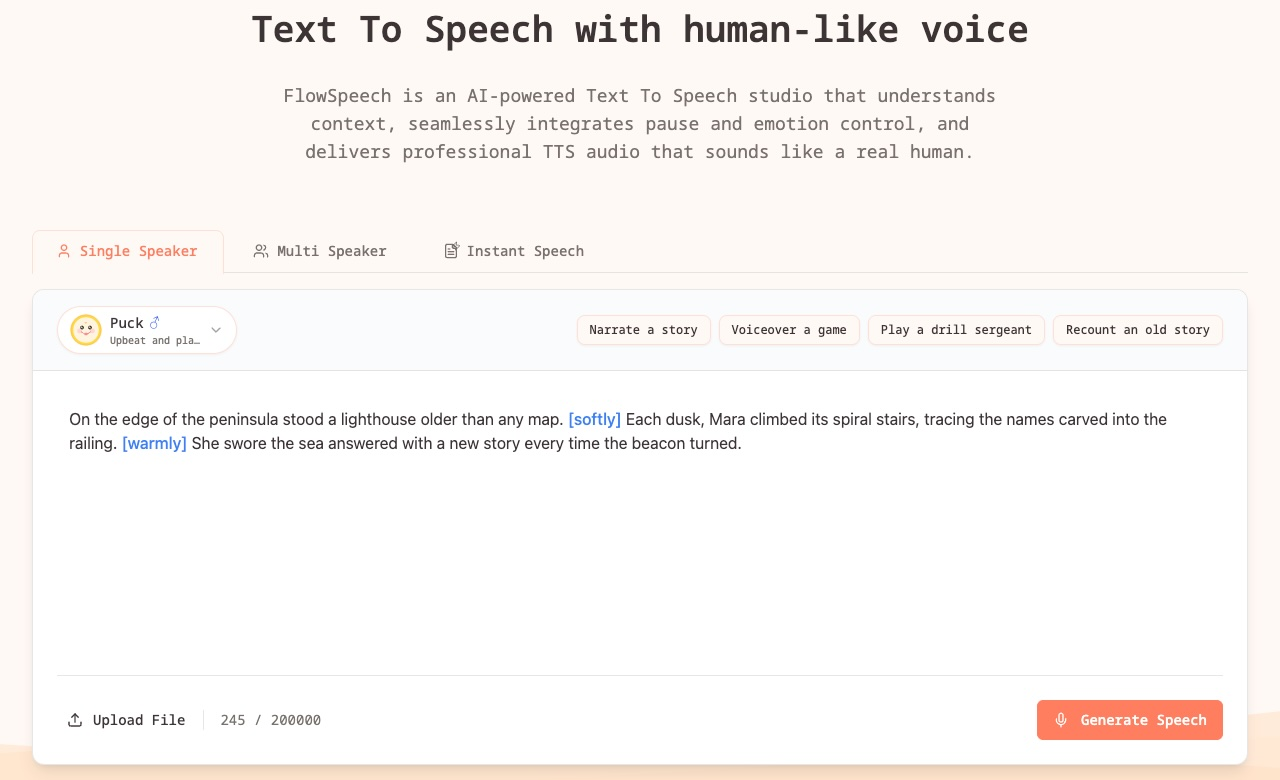
The challenge of producing natural-sounding speech from text, often hindered by robotic intonation, is addressed by tools like FlowSpeech. This purpose-built Text-to-Speech (TTS) studio is designed to convert written text into human-like speech, with its primary differentiation being context-aware emotion delivery. It analyzes the sentiment and nuance of a script to generate expressive voiceovers.
Precision Control for Expressive Audio Generation
FlowSpeech’s core capability is its context-aware emotion delivery, which automatically integrates appropriate sentiment into generated speech. Users can also implement granular control over speech nuances by embedding manual emotion and accent tags, such as [whisper] or [strong British accent], directly into the text. Precise pause controls, specified as [⌛1.0s], further allow for fine-tuning of speech rhythm. This direct text manipulation mitigates the necessity for subsequent post-production editing in a Digital Audio Workstation. Supported output audio formats include MP3 (default), Opus, AAC, FLAC, WAV, and PCM.
Simplifying Multi-Speaker Content Creation
- Single Speaker auto-markup: Automatically applies consistent voice character and expressive TTS when processing scripts for a single speaker.
- Multi Speaker auto voice matching: Detects and assigns suitable AI voices to different speakers within a script, enabling the creation of complex dialogues.
Credit System and Character Limits for High-Volume Use
FlowSpeech uses a credit-based usage model. Free access includes 5,000 credits per month for guests, with a 5,000-character limit per request. Signed-in free users receive 10,000 credits per month and a 10,000-character limit per request. Paid plans, such as the Basic tier starting at $12 per month, billed monthly, provide 200,000 credits per month and support up to 200,000 characters per request, offering access to over 30 voices. Higher tiers, like Pro and Scale, offer increased credit allowances to accommodate more extensive usage. The credit system and character limits directly influence the volume of text-to-speech conversion possible for individual users or teams. The platform supports over 70 languages.
FlowSpeech’s design addresses the automation of expressive speech generation for content creators, digital marketers, and educators, producing high-quality audio for tasks such as audiobook narration and marketing videos. Its API enables integration into existing workflows. Text input can be directly pasted or uploaded from various document and image files, including PDF, DOC, DOCX, PPT, PPTX, TXT, RTF, EPUB, and image files. While FlowSpeech advances the capabilities of AI-driven text-to-speech by focusing on context and expressive control, its capacity to fully replicate the spontaneous variations and subtle improvisations of human voice actors for highly expressive performances remains an area for further development.